

今天(3月19日),小米悄然上线了 MiMo-V2 系列三款重磅模型。作为一个从 V1 一路追过来的体验者,说实话,看到参数的那一刻,我愣了一下。
目前,这些模型已经登陆 Xiaomi miclaw、MiMo Studio、金山办公、小米浏览器,通过 OpenClaw、OpenCode、KiloCode、Blackbox、Cline 接入,可限时免费体验一周。

从手机公司到大模型玩家,小米走了多远?
先说个背景。很多人对小米做 AI 大模型这件事,第一反应是"手机厂凑什么热闹"。这不奇怪,毕竟在大家的印象里,小米的核心标签是性价比、是供应链、是雷总的"Are You OK"。
但其实小米布局大模型的时间比很多人想象的要早——2023年4月就组建了AI大模型团队。2023年8月,雷军明确提出小米的技术路线:轻量化和本地部署。同年,首款模型 MiLM-6B 登陆 GitHub。而小米大模型的核心负责人,是一位95后的AI天才——罗福莉。
我第一次看到 MiMo-V2-Flash 的技术报告时,就觉得不太一样。那些架构设计不是在堆参数炫技,而是在解决实际工程问题:怎么跑得更快?怎么花更少的钱?怎么塞进手机和车里?这种"工程洁癖",确实很小米。
今天,V2 系列的发布,可以说是把这份执念推到了极致。
今天的主角:MiMo-V2-Pro——万亿参数的"Agent怪兽"
先聊重头戏。
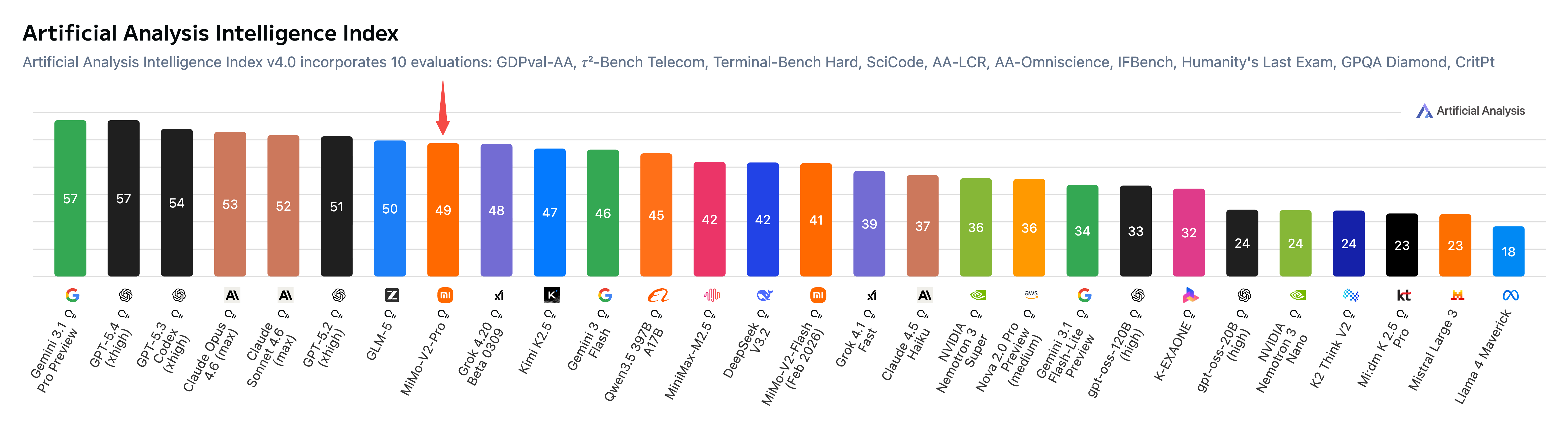
MiMo-V2-Pro,小米把它定位为"专为现实世界高强度 Agent 工作场景而打造"的旗舰模型。我们看看它到底有多"硬核":
| 指标 | 数据 |
|---|---|
| 总参数量 | 超过1T(对,一万亿) |
| 激活参数量 | 42B |
| 架构 | MoE + 创新混合注意力 |
| 上下文长度 | 1M(100万 token) |
| API 定价 | 256K内:1/M输入,3/M输出;1M内:2/M输入,6/M输出 |
(万亿参数,听起来就很有分量)
一万亿参数意味着什么?这意味着它理论上可以学习和存储极其庞大的知识体系。但更让我在意的是那个42B激活参数——这说明小米用了 MoE(混合专家)架构,每次推理只激活总参数的一小部分,但效果却能逼近甚至超越全量参数模型。
换句话说:它很强,但没有你想象的那么"贵"。
再说那个 1M 上下文长度。这不是一个小数字。100万 token 大约相当于一本完整的长篇小说。你可以把一整个项目的代码库扔给它分析,也可以把几十页的学术论文一次性让它理解和总结。
在 Agent 场景——比如让 AI 自主调用工具、完成多步骤复杂任务——这种长上下文能力就变成了刚需。Agent 需要在漫长的交互过程中记住所有的上下文,1M 的窗口意味着它不会在第50轮对话时"忘了"你一开始要求它做的事。
定价方面,说句实话,在这个量级的模型里,小米给出的价格相当有竞争力。$1/M 输入的价格,已经和 DeepSeek-V3.2 接近了。
V2-Flash:那个速度与成本的"甜点"
虽然今天的焦点是 Pro,但如果不提 V2-Flash,这篇文章就不完整。去年12月发布的 MiMo-V2-Flash,才是小米真正"秀肌肉"的起点。
它的参数是 309B 总量 / 15B 激活,看起来比 Pro"小"不少,但它的杀手锏从来不是体量,而是速度和成本。
说几个让我印象深刻的数字:
- 推理速度:150 tokens/s,大约是 DeepSeek-V3.2 的3倍
- 价格:0.1/M输入,0.3/M输出——是的,你没看错
- AIME 2025 数学竞赛:开源模型前两名
- SWE-bench Verified(修bug测试):73.4%,超越所有开源模型

(150 tokens/s,读起来像刷屏一样)
我实际体验了一下,确实快得有点离谱。20秒吐出4000字,而且不是胡言乱语那种"快",是真的在认真回答你的问题。这种体验,说实话,比很多更大、更贵的模型还要好。
而小米做到这一点的技术手段,我觉得非常值得聊聊。
混合注意力:像人一样"选择性专注"
V2-Flash 用了一个很聪明的设计:全局注意力与滑动窗口注意力 5:1 的混合方案。
简单说,大部分层只看最近128个 token(局部窗口),每隔一层才用全局注意力扫一遍全文。这就像你读小说时的状态——大部分时间盯着当前这一页,偶尔翻回去看看人物关系表。
最有趣的是那个 attention sink bias。罗福莉(MiMo负责人)在分享中提到一个反直觉的发现:窗口大小128是"最佳甜点值",盲目扩大到512反而性能下降。这说明小米做过大量精细的实验,找到了效率和效果的最佳平衡点。
MTP:别一个字一个字"吐"了
传统大模型生成文字是一口一口吐的,吐一个 token 才知道下一个是什么。V2-Flash 的 Multi-Token Prediction(MTP) 机制让它能并行预测多个 token。
实测平均能一次接受2.8到3.6个 token,速度直接提升2到2.6倍。而且这个 MTP 不是后期加的"外挂",而是在预训练阶段就深度集成的。
用罗福莉的话说,小米借鉴了 Thinking Machine 的 On-Policy Distillation 方法,实现了只用传统方法 1/50 的算力,就能让学生模型达到教师峰值性能。
说人话就是:别人花50块钱做到的事,小米花1块钱就做到了。 这在算力成本居高不下的今天,简直是降维打击。
同场加映:Omni 和 TTS——小米的"全栈梦"
今天小米一起发布的,还有两款模型:
MiMo-V2-Omni:全模态理解
"Omni"是"全能"的意思。这款多模态模型能同时处理文本、图像、音频等多种模态输入。虽然目前技术细节还没有完全公开,但从名字和定位来看,小米是在往多模态融合的方向发力。

(多模态:让AI不只会读文字,还能"看"和"听")
说实话,这一步很重要。当 Agent 需要处理真实世界的问题时,它不可能只看文字。它需要理解截图、识别界面、处理语音指令。Omni 的存在,就是为了解决这个"最后一公里"的问题。
MiMo-V2-TTS:语音合成大模型
TTS 即 Text-to-Speech,把文字转成语音。小米做语音合成其实不意外——小米的硬件生态(小爱同学、智能音箱、车机系统)对语音能力有天然的需求。
我个人的期待是:如果能把 MiMo 的语言理解和 TTS 的语音合成完美结合,未来在小米手机和小米汽车上的语音助手体验,可能会有一个质的飞跃。
说点掏心窝的话
小米做 MiMo 这件事,我一直在关注。说几条我的个人观察和判断:
1. 小米的路径和其他家完全不同。
OpenAI 在追通用智能的天花板,DeepSeek 在搞开源生态,Google 在做多模态旗舰。小米呢?小米在想怎么把这个东西塞进手机里。
这不是贬义。这恰恰是最难、最有价值的方向之一。当所有人都在追逐更大的模型、更多的参数时,小米在想的是:怎么让这个模型在有限的算力下跑得更快、更省、更稳。
2. 开源是一种态度,更是一种自信。
V2-Flash 完整开源,MIT 协议,技术报告详细到令人发指的程度——连 MTP 的三层实现都开源了。这种做法在国内大厂里确实少见。它传递的信息很明确:小米不怕别人看,甚至欢迎别人用。
3. 工程优先,而非学术优先。
读完技术报告,我的感受是:小米的创新更多体现在工程落地层面,而不是发论文炫指标。混合注意力、MTP、MOPD……每一个技术点的出发点都是"怎么在实际场景中更好用",而不是"怎么让论文更好看"。
这种风格,说实话,挺小米的。
一张图总结
| 模型 | 定位 | 核心亮点 |
|---|---|---|
| MiMo-V2-Pro | 旗舰Agent模型 | 万亿参数、1M上下文、专为Agent设计 |
| MiMo-V2-Flash | 极致性价比 | 150tokens/s、$0.1/M输入、全面开源 |
| MiMo-V2-Omni | 多模态理解 | 文本+图像+音频全模态融合 |
| MiMo-V2-TTS | 语音合成 | 为小米硬件生态打造的语音能力 |

(从手机到汽车,小米的 AI 布局正在串联起来)
最后
小米从做手机到做汽车,从做IoT到做大模型,这条路走得很长也很坚定。
MiMo-V2 系列不是完美的——Pro 的 API 定价虽然有竞争力但不算便宜,Omni 的技术细节还需要更多验证,TTS 的实际效果也有待体验。但方向是对的:把 AI 能力嵌入硬件生态,让技术真正服务普通人。
如果你是一名开发者,V2-Flash 的 API 现在还在免费试用期内,强烈建议去试试。如果你只是普通用户,小米的智能助手在未来半年到一年内,体验上应该会有质的变化。
小米说"为发烧而生"。这一次,MiMo 让 AI 真正烧起来了。
本文写于 2026年3月19日,信息来源于小米官方发布及公开报道。如需转载,请注明出处。
往期精彩:
【好玩儿的Docker项目】用MuMuAiNovel自动写小说,docker一键部署,月入过万不是梦
最高月享 9 万次请求!联通云 12000 个免费 AI 开发 Coding Plan 套餐开抢
【好玩的docker项目】利用Navidrome自建个人音乐服务平台
欢迎大家关注我的微信公众号:踏浪而行生活圈,如果你也喜欢前沿的科技与技术,请不要错过这个宝藏博主

评论区